CONFLEX DOCK Algorithm
CONFLEX DOCK is a program for protein–peptide docking based on a four-body statistical coarse-grained potential.
Overview of the Four-Body Statistical Coarse-Grained Potential
Tropsha and colleagues compared the stability of native and non-native forms of proteins using a coarse-grained mode.
In this process, the potential score is calculated from the tetrahedral representation of the representative points, which is obtained by Delaunay tessellation.
Krishnamoorthy, B.; Tropsha, A. Bioinformatics, 19, 1540–1548 (2003).
This four-body statistical coarse-grained potential was applied to protein–peptide docking by Aita and colleagues at Saitama University.
T. Aita, K. Nishigaki, Y. Husimi, Comput. Bio. Chem. 34, 53–62 (2010).
Based on this four-body coarse-grained potential, we developed a protein–peptide docking program.
T. Yamamoto, Y. Ikabata, H. Goto, “Reconstruction of Four-Body Statistical Pseudopotential for Protein-Peptide Docking”, J. Comput. Chem., Jpn.-Int. Ed., 2024, 10, 2023-0039.
Combination of four amino acid residues
To calculate the potential score, tetrahedra comprising quadruplets of amino acid residues are considered.
Each tetrahedron belongs to one of the following five classes:

| Class | α | Description |
|---|---|---|
| {1,1,1,1} | 0 | All four residues are non-consecutive in the primary sequence. |
| {2,1,1} | 1 | One pair of consecutive residues and two other residues, each of which is non-consecutive with respect to the others. |
| {2,2} | 2 | There are two pairs of consecutive residues, with each pair non-consecutive with respect to the other pair. |
| {3,1} | 3 | There are three consecutive residues, and the remaining one residue is non-consecutive with respect to the others. |
| {4} | 4 | All four residues are consecutive in the protein's primary sequence. |
Potential Score
The potential score is calculated using the following formula.
Here, is the actual frequency of occurrence. is the expected frequency of occurrence.
The frequency of occurrence is calculated by performing Delaunay tessellation of the protein to generate a large number of tetrahedra and then counting them.
In this process, Delaunay tessellation divides the point cloud in space so that the minimum angle of the tetrahedra is maximized and the circumscribed sphere of each tetrahedron is minimized.
The expected value P is calculated using the following formula.
Here, each variable is defined as follows.
| , , , | The frequency of occurrence of i, j, k, and l in the dataset |
| The probability that the tetrahedron belongs to class α | |
| η | The number of types of amino acid residues constituting the tetrahedron |
| tν | The number of residues of typeν in the tetrahedron |
CONFLEX DOCK Simulation Procedure
Docking simulations using CONFLEX DOCK are performed according to the following procedure.
- Placement of search points on the protein surface
- Exploration of peptide positions (binding poses)
- Sorting of results based on potential scores and prediction accuracy metrics (RMSD, GTGD)
- Clustering of binding poses
Placement of search points - Defpol Method
This method arranges search points spherically to cover the protein and moves them toward the surface along vectors pointing to the protein centroid.
Pomelli, C. S.; Tomasi, J. J. Comput. Chem., 1988, 15, 1758–1776.

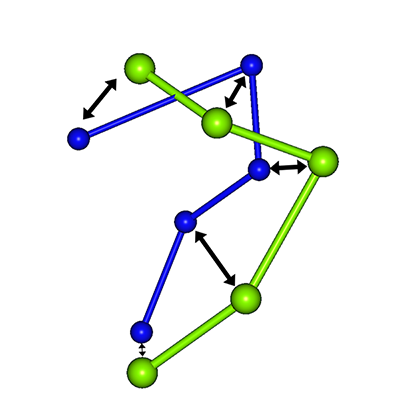
- Search Algorithm
-
The docking search proceeds as follows:
- Place a peptide amino acid residue at a search point, form a tetrahedron with one amino acid residue from the peptide and three from the protein, and evaluate the score.
- Place the next amino acid residue at another search point and evaluate the score.
- Selection of search points according to predetermined criteria
- Repeat the above evaluation and search.
This procedure is regarded as a tree structure. Within this framework, an elitist strategy is employed: N nodes with the highest scores are selected from the available search points, and the subsequent search is carried out from these nodes.
The figure illustrates the case where N equals 2.
Evaluation methods for prediction accuracy
RMSD:Root Mean Square Deviation
It is a calculation method that compares the positions of each amino acid residue individually.
Here, each variable is defined as follows.
| N | Number of amino acid residues in the peptide |
| Coordinates of the i-th amino acid residue point | |
| Coordinates of the i-th amino acid residue point in the experimental structure |
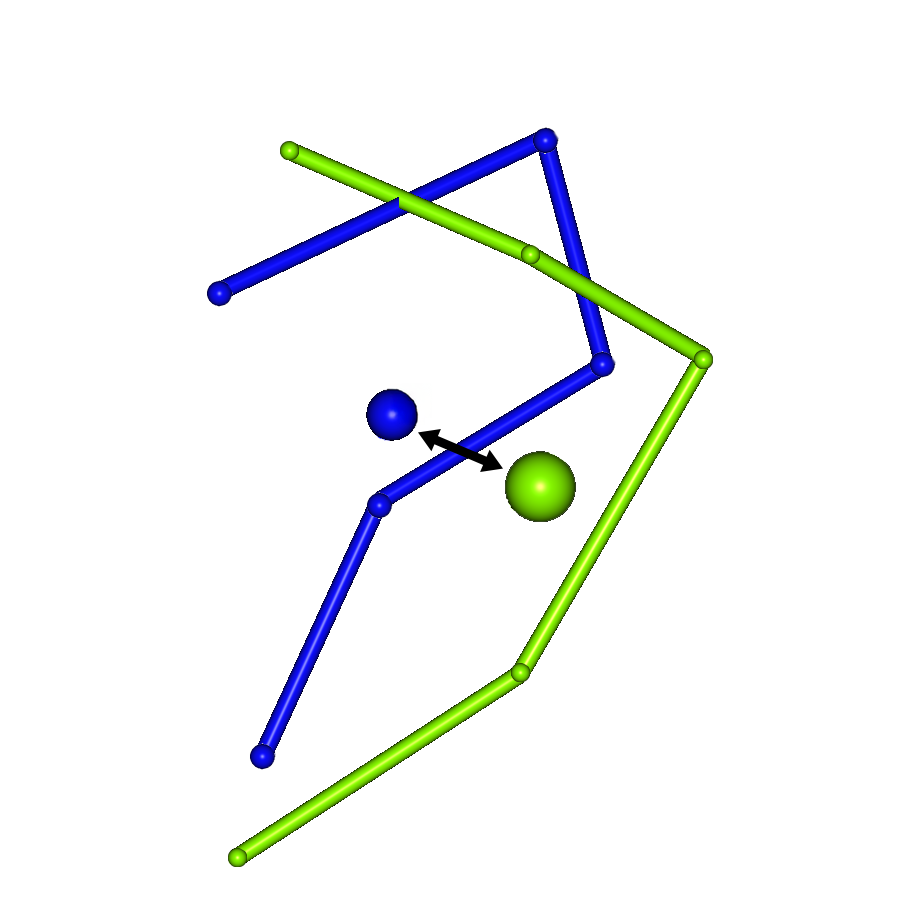
GTGD:Geometric center To Geometric center Distance
It is an index that represents the degree of coincidence (similarity) of geometric centers.
Here, each variable is defined as follows.
| N | Number of amino acid residues in the peptide |
| Coordinates of the i-th amino acid residue point | |
| Coordinates of the i-th amino acid residue point in the experimental structure |